Regular Expressions
advertisement

-Joseph Beberman
*Some slides are inspired by a PowerPoint
presentation used by professor Seikyung Jung,
which was derived from Charlie Wiseman.
Regular expressions are all over the place.
All syntaxes are almost identical, but for what
it’s worth I will be using the syntax tied to
Unix systems.
In computer science, regular expressions are used to
locate strings based on a pattern.
Search for every email address in a file? Regular
expressions make it easy.
Often referred to as regexp, regex, etc.
For instance: A phone number is three digits, followed by a
dash, three digits, a dash, and then four digits (“555-5555555”). You can make a regular expression which matches
all phone numbers by indicating that pattern.
For reference: [0-9]{3}-[0-9]{3}-[0-9]{4}
Consider values of currency. How could you
describe in English any/all monetary values
(including cents) with a single pattern?
ie. $50.25
Consider values of currency. How could you
describe in English any/all monetary values
(including cents) with a single pattern?
ie. $50.25
Dollar sign, any number of digits, period, two
digits.
Consider values of currency. How could you
describe in English any/all monetary values
(including cents) with a single pattern?
ie. $50.25
Dollar sign, any number of digits, period, two
digits.
For reference: \$[0-9]+\.[0-9]{2}
Using it to showcase regular expressions.
◦ It actually stands for Global Regular Expression
Parser
A command available on most if not all Unixlike systems.
Seem to be incredibly popular command for
system administrators.
grep is used to do text-based searching,
generally on the Linux command line or in
scripting
Takes two arguments
Generic format: grep STRING FILE
It prints every line of FILE that has STRING in it.
Example: grep root /etc/passwd
◦ »Prints out all lines in the /etc/passwd file that contain
the string "root"
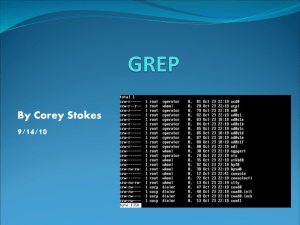
The contents of /etc/passwd
grep ‘root’ /etc/passwd
What does this tell you?
◦ 2 lines contain the string “root”
◦ Highlights exactly where the string was matched
Grep has a number of options, and even
though it’s off topic knowing some may help
you understand the power of grep/regexps.
-i » ignore case
-v » negation
◦ grep –v hello filename.txt
Would return every line of filename.txt without the
word hello in it.
How does grep use regular expressions?
◦ Again: stands for Global Regular Expression Parser
Recall the format: grep STRING FILE
The STRING is actually interpreted as a
regular expression.
Note: I will be using the –E option for grep
◦ Don’t worry about it, it essentially enables all
regexp functionality.
First thing’s first… we need a text file to
search!
I’ve taken the time to make a simple text file
which will help me show some simpler
regular expressions.
How do you up your game from literal strings like
“root”, to creating patterns? Regexs have their
own syntax.
To start: parenthesis are used for grouping “or
statements”.
To match one thing or something else, you group
them in parenthesis and separate them with
pipes.
◦ (joe|Joe) will match the string “joe” or “Joe”
◦ (hello|goodbye|sup) matches “”hello” “goodbye” or “sup”
You can specify a range of characters within
brackets.
◦ For example [a-z] will match any lower case letter.
◦ [A-Z] any upper case letter
◦ [0-9] any digit
Now the pattern is any digit.
Now the pattern is digits 0 to 5.
You can match one thing after another.
◦ For example: [a-z][0-9] will match any lower case
letter followed by a number. Now we are starting to
see patterns!
When specifying one range or another, you
don’t need a pipe.
◦ For example [a-zA-Z] will match any lower or upper
case letter.
◦ [0-9a-zA-Z] will match any alphanumeric character
Now it’s time to get more specific. What if
you want to find something that occurs
multiple times in a row?
The +, *, ?, and {} special characters specify
how many times you want the pattern directly
in front of them to occur.
◦ Ex. [a-zA-Z]+
◦ The + modifies the grouping in front of it
+ » one or more instances
◦ [a-zA-Z]+ would match any string of lower/upper case
letters at least 1 letter long.
* » zero or more instances
◦ [0-9]* would match any number of digits, or none at all.
? » zero or one instance (aka optional)
◦ [a-zA-Z]+ would match a single letter or none at all.
[a-z]+[0-9]*[A-Z]?
◦ ade7E
◦ cpB
◦ F12CP X
◦ Please ask questions here if you’re confused!
{} » specific or range
◦ {3} or {4,7}
◦ ‘[0-9]{3}-[0-9]{3}-[0-9]{4}’ for a phone number
Now we can make a regular expression that matches
emails!
Let’s try now…
Now we can make a regular expression that matches
emails!
Let’s try now…
Any alphanumeric sequence, @, any
alphabetical sequence, ., any lower case
sequence
Now we can make a regular expression that matches
emails!
Let’s try now…
Any alphanumeric sequence, @, any
alphabetical sequence, ., any lower case
sequence
‘[a-zA-Z0-9]+’
Now we can make a regular expression that matches
emails!
Let’s try now…
Any alphanumeric sequence, @, any
alphabetical sequence, ., any lower case
sequence
‘[a-zA-Z0-9]+@’
Now we can make a regular expression that matches
emails!
Let’s try now…
Any alphanumeric sequence, @, any
alphabetical sequence, ., any lower case
sequence
‘[a-zA-Z0-9]+@[a-zA-Z]+’
Now we can make a regular expression that matches
emails!
Let’s try now…
Any alphanumeric sequence, @, any
alphabetical sequence, ., any lower case
sequence
‘[a-zA-Z0-9]+@[a-zA-Z]+.’
Now we can make a regular expression that matches
emails!
Let’s try now…
Any alphanumeric sequence, @, any
alphabetical sequence, ., any lower case
sequence
‘[a-zA-Z0-9]+@[a-zA-Z]+.[a-z]+’
Weird… why did we match that third line?
. Is a special character which takes the place of
anything.
That means ‘t.o’ would match two, too, t2o, or
many other things.
That’s how it matched below. The . matched 0!
So how do we avoid matching weird things like
j03b130@h0tma?
◦ [a-zA-Z0-9]+@[a-zA-Z]+\.[a-z]+’
You can escape special characters by putting \ in
front of them.
◦ So \. means a literal period.
◦ Note: Escape \ by putting \ in front of it! \\
So \\ means a literal back slash.
◦ Double Note: the space character is matched by \s
effectively escaping the s character.
^ » Indicates the start of a line
Notice how it didn’t match ever line with “I” in
it, only the ones which start with I.
Vs.
$ » indicates end of a line
Syntax:
◦
◦
◦
◦
◦
◦
◦
◦
◦
^ start line
$ end line
+ one or more
* zero or more
? zero or one
. replace with anything
{n} n times
{n, m} n to m times
(string1|string2) matches string1 or string2
What does this match?
[0-9]{3}-[0-9]{3}-[0-9]{4}
What does this match?
[0-9]{3}-[0-9]{3}-[0-9]{4}
Phone numbers!
What does this match?
\$[0-9]+\.[0-9]{2}
Money values
Example: What does this match?
‘(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)'
Example: What does this match?
‘(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)‘
That actually matches valid IP addresses.
(I found it online though. Credit to SASIKALA of thegeekstuff.com)
Regular expressions simply indicate a pattern.
What is important is that the pattern can be
searched for as opposed to a literal string.
That means instead of searching for a specific
phone number string input, you can search for
any existing phone number with ease by
matching the pattern that all phone numbers
follow.
Common tasks that regular expressions are used for:
It finds strings that match a given syntax.
◦ -Ctrl-F, anyone? There are tools to add regular expression
functionality to Ctrl-F, at least on Chrome.
◦ -Tool: Regular Expression Searcher
Once you find said strings based on the pattern, there
are limitless possibilities as to what you can do with
those matches.
Substitution: Replace all matching strings.
◦ -Ctrl-H (on word), anyone?
Splitting: Split strings based upon matches.