
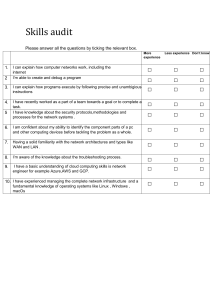
Throughout my professional journey as a Data Engineer, I have amassed eight years of experience in data analysis, quantitative analysis, and analytics solutions development. I have worked extensively with various tools and techniques, demonstrating proficiency in handling structured and unstructured data, data cleaning, and descriptive analysis. My expertise extends to developing and implementing machine learning algorithms and statistical models to solve complex business problems and facilitate data-driven decision-making. One of the key areas where I have excelled is in utilizing Apache Airflow, an advanced workflow management tool, to orchestrate and schedule complex data pipelines and workflows efficiently. This skill has enabled me to streamline data processing and ensure timely and reliable data integration. In addition, I have gained significant experience in using Informatica Cloud, Informatica PowerCenter, and other related Informatica products to build and manage complex ETL workflows for various data sources and destinations. This expertise has been instrumental in ensuring seamless data integration across diverse systems and platforms. I have also showcased proficiency in designing and implementing scalable data models in Snowflake and Redshift, focusing on data integrity, organization, and optimized query performance for efficient data retrieval and analysis. My strong command of PostgreSQL, including designing and implementing relational database schemas, writing complex SQL queries, and optimizing database performance, has further enhanced my data engineering capabilities. As a data engineer, I have leveraged my knowledge of Agile methodologies to implement Agile metrics and reporting mechanisms, providing visibility into project progress, team performance, and product quality. Furthermore, I have utilized visualization tools such as Tableau and PowerBI to create interactive dashboards that present complex datasets in a clear and concise manner, driving data-driven decisionmaking. My experience extends to implementing data extraction, transformation, and loading (ETL) processes using tools such as Ab Initio, Talend, and Apache Kafka, ensuring accurate and efficient data integration from various sources into centralized data repositories. I have also demonstrated expertise in working with AWS services, including AWS Glue, Amazon S3, and Amazon Redshift, for data processing, storage, and analysis. While my proficiency in AWS and data integration is evident, I recognize the importance of continuously updating my knowledge in AWS. As technology evolves, so do the best practices and standards in the industry. Staying up to date with the latest advancements in AWS will enable me to leverage new features and capabilities to develop even more efficient and robust data engineering pipelines. It will also ensure that I remain at the forefront of data integration techniques and can provide the most effective solutions to meet evolving business needs. In conclusion, my extensive experience in data analysis, quantitative analysis, and analytics solutions development, coupled with my proficiency in AWS, ETL, and data integration, has positioned me as a skilled and versatile Data Engineer. By constantly updating my knowledge in AWS, I can continue to deliver innovative and reliable data engineering solutions while staying ahead in this rapidly evolving field.




![Ultimate AWS Certified Cloud Practitioner - 2020 [BRAND NEW] - Study Plan](http://s3.studylib.net/store/data/025372299_1-8ea074b0aec20f2ec0f8d759013912ff-300x300.png)
